
This post is an early preview of Production Ready GraphQL, a book I recently released on building GraphQL servers that goes into great detail on building GraphQL servers at scale: https://book.productionreadygraphql.com Check it out if you enjoy this kind of content!
If you’re getting started with GraphQL, or already running but hitting performance issues with execution of GraphQL queries. Chances are you’ve read something or heard something like “Just use dataloader!”. Let’s try to demystify wh we often face data loading issues with GraphQL, and what the dataloader pattern we hear so much about is all about.
The GraphQL schema is what allows clients to know the possibilities exposed by the server, and the server to validate incoming client queries against its interface. However, a GraphQL server usually needs another very import concept to be useful: resolvers. We can see resolvers as simple functions that return the data for a certain exposed GraphQL field. Usually, resolvers will be a function of a field’s parent object (the object that the parent resolver returned), arguments if there are any, and sometimes an additional context argument, which can carry contextual and global information about a query that can be used during execution.
 The unit of GraphQL execution: a resolver function
The unit of GraphQL execution: a resolver function
While a very powerful concept that allows a GraphQL engine to dynamically generate client representations, the per-field resolver pattern leads to certain unexpected issues when used naively. This is the case with data loading. The problem is that resolvers live in their own little world (In fact, can even be executed in parallel along others). This means a resolver with data requirements has no idea if this data has been loaded before, or if it will be loaded after. For example, three resolvers that need to load a certain user could end up making the same SQL query.
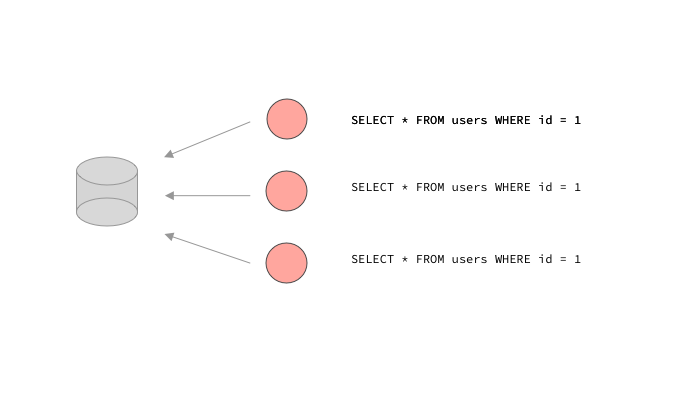 Resolvers have no idea if other resolvers will end up asking for the same data requirements
Resolvers have no idea if other resolvers will end up asking for the same data requirements
Most servers will actually resolve queries serially, meaning one field after the other. Take a look at the execution of a typical query that loads the current user’s name and age, all their friends, as well as the best friend of each their friends.
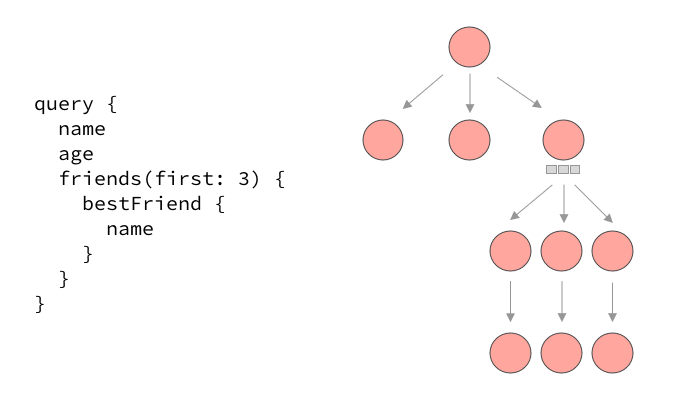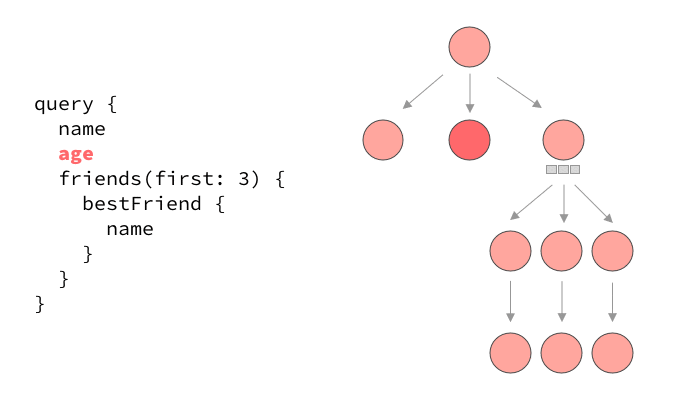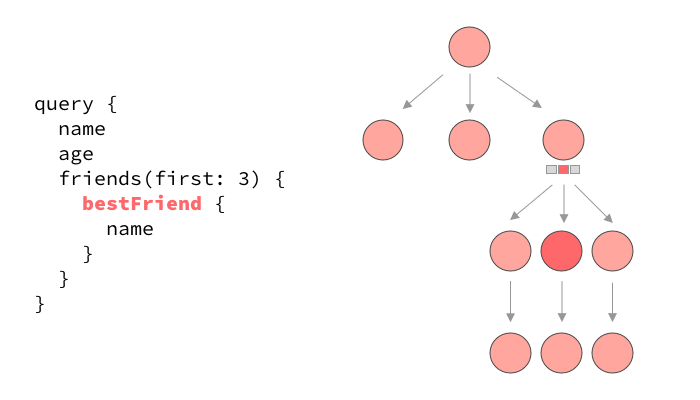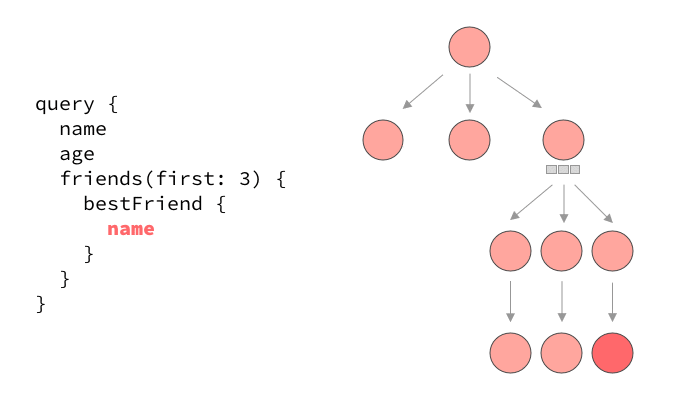 The serial execution of a typical GraphQL query
The serial execution of a typical GraphQL query
Looking at this GraphQL query from an external eye, we can imagine how we would want to load the data that we need. In fact, if were were dealing with an endpoint based API, where the serialization logic for the whole payload is often collocated or at least executed in a shared context, we’d know how to do this. Here we want to load the current user, load the first 3 friends from a join table, and then load these 3 friends at once using their IDs. Finally, take the best_friend_id from each user and load them all. Looking at a resolver graph, we’d have the 4 following queries:
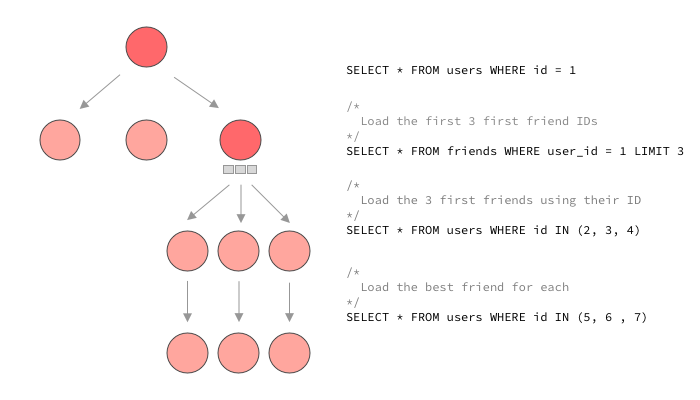 How we’d usually want to load data for this query.
How we’d usually want to load data for this query.
As we just saw, this is hard to achieve with our resolver concept. How can the resolver for friends(first: 3) know that it needs to preload the best friend for each, this is the responsibility of the bestFriend field! While the fact that the loading of bestFriend is colloquated in the bestFriend resolver is great, a naive execution of this query would rather look like this:
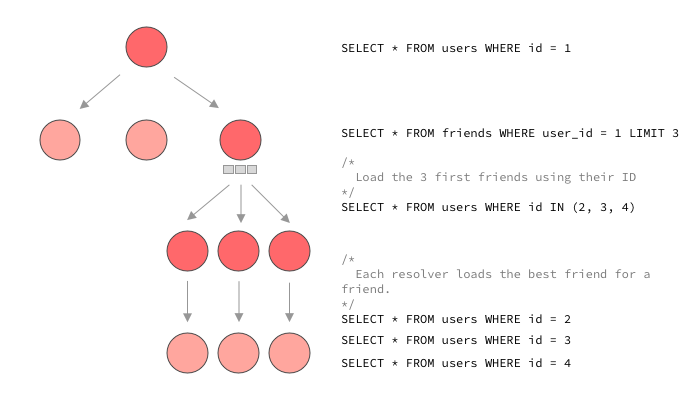
As you can see, a typical GraphQL execution would likely make 6 queries instead of 4 here. Ask for 50 users and we would have 53 queries while the other solution still works with 4 SQL calls! This is clearly not acceptable and will fall apart very quickly as your data sets grow and more queries of that kind are ran against your GraphQL API. Now that we see the problem, what can we do about this? There’s multiple ways to look at the problem. The first one is to ask ourselves if we could not find a way to load data ahead of time instead of waiting for child resolvers to load their small part of data. In this case, this could mean for the friends resolver to “look ahead” and see that the best friend will need to be loaded for each. It could then preload this data and each bestFriend resolver could simply use a part of this preloaded data.
This solution is not very commonly used, and that’s quite understandable. A GraphQL server will usually let clients query data in the representation they like. This means our loading system would need to adapt to every single scenario of data requirements that could appear very far into a query. It is definitely doable, but from what I’ve seen so far, most solutions out there are quite naive and will eventually break in most complex data loading scenarios. There’s a more popular approach out there that is most commonly referred as “dataloader”. This is because the first implementation of this pattern for GraphQL was released as a javascript library called dataloader.
Enter Lazy Loading
The idea behind Dataloader is kind of the opposite of the “look-ahead” solution we just talked about. Instead of being eager about loading data, and having to handle all possible cases ahead, the dataloader style loading pattern is purposefully very lazy about loading data. Let’s dive into it.
The first principle to understand is that when using the dataloader approach, we take an asynchronous approach to resolvers. This means resolvers don’t always return a value anymore, they can return somewhat of an “incomplete result”. For the sake of this post, we’ll talk about the most commonly used “incomplete result” objects, promises.
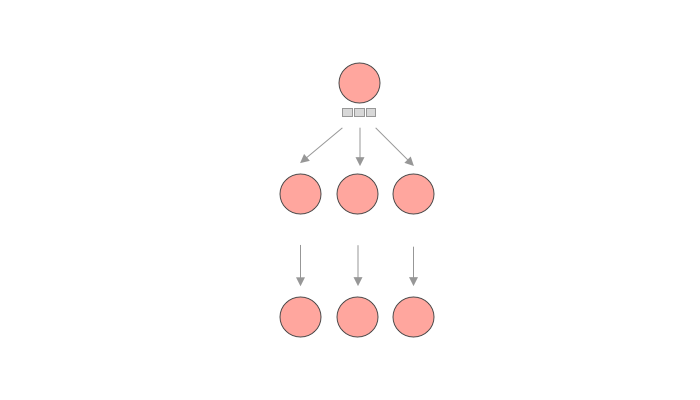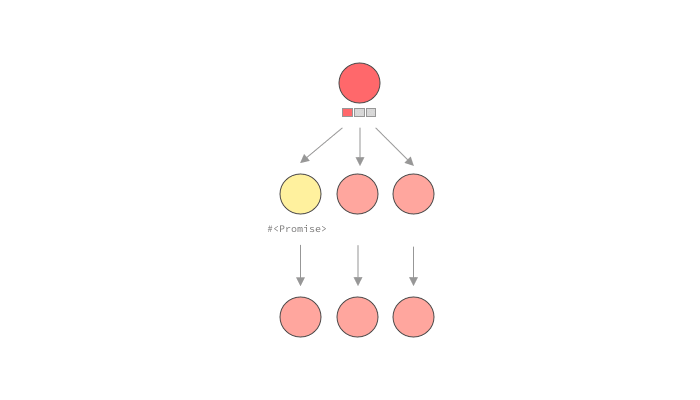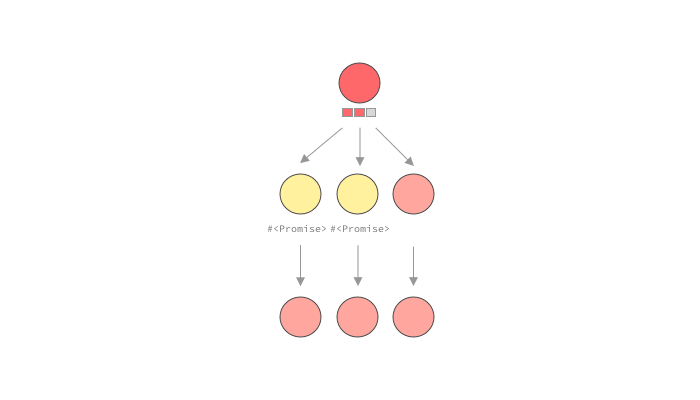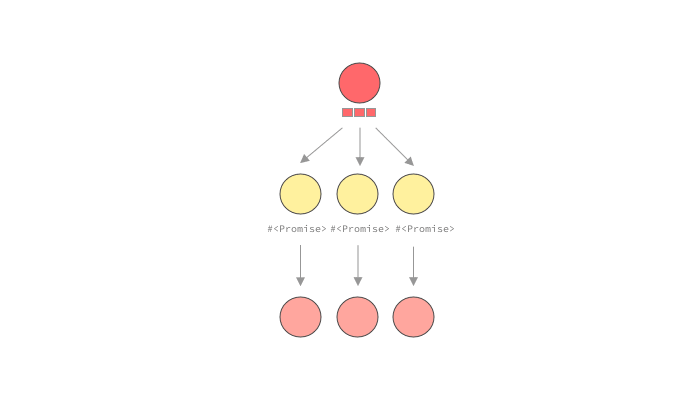
As you can see, while the standard execution strategy would execute the query in a depth-first-search approach, resolving child fields before other fields at the same level, we have a different approach here. When a resolver wants to fetch data, instead of fetching it right away, it will indicate to the executor that it will eventually have data, but that for now it should proceed to the next resolver on the same level of the query tree.
The next step to understand how this eventually works is to introduce the concept of loaders. Loaders are a simple idea, even though their implementation may be complex. The basic idea is that when an individual resolver has data needs, it will go through a loader instead of going straight to a data store. The role of loader is to collect identifiers required to fetch objects from individual resolvers, and to batch load this data in a more efficient way.
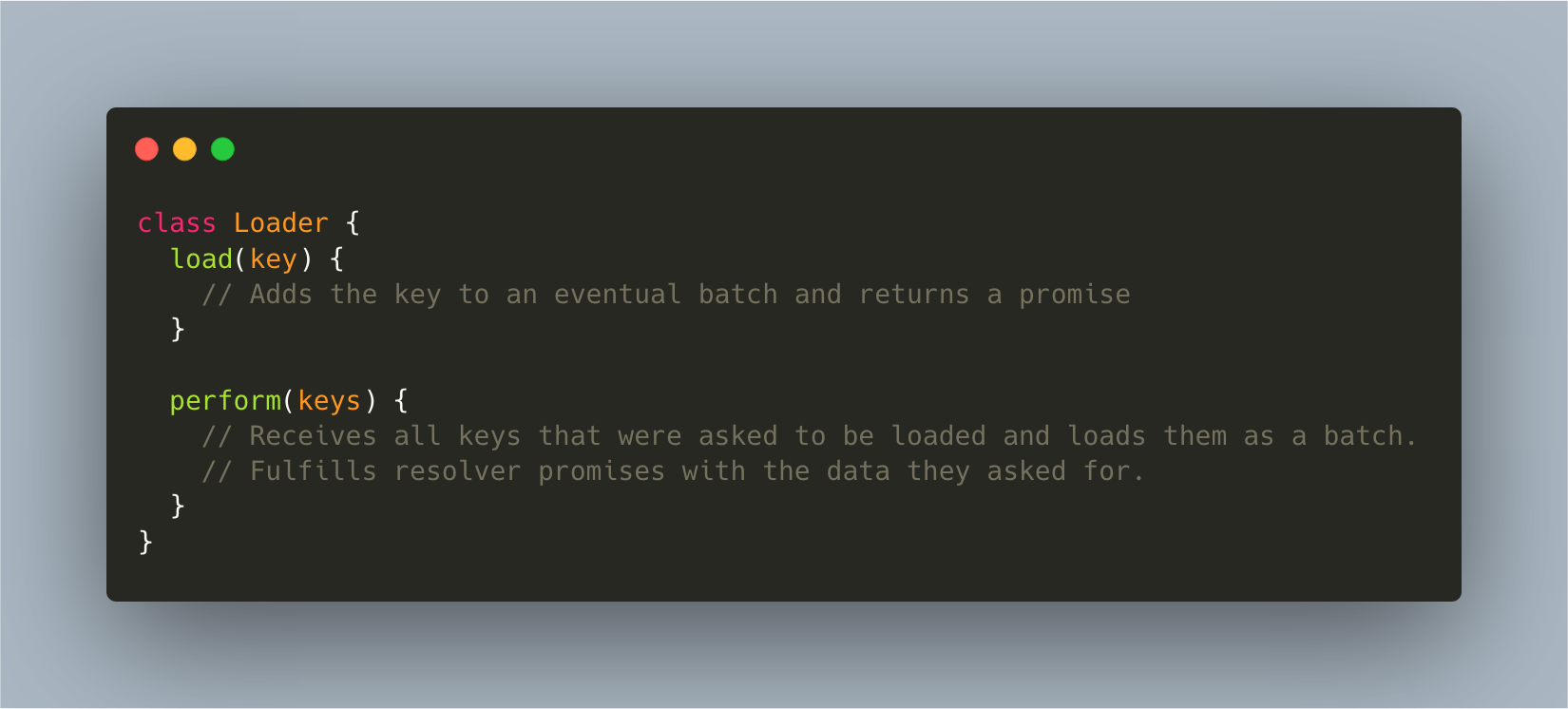 A typical dataloader style API
A typical dataloader style API
The typical abstraction for a loader is a class or object with two main methods:
-
load takes as an argument the loading key for the data the caller is interested in and it returns a promise, which will eventually be fulfilled with the data the caller asked for. This method is used within resolvers
-
perform (batchFunction ) Takes all the accumulated keys that the load function calls added, and loads the data in the most efficient way. This method is usually either defined by us, or calls a batch function we’ve provided.
Here’s an example of how that could possibly look in ruby:
)](https://cdn-images-1.medium.com/max/2356/1*mQk0aPc5O7AQuR2XPy2ytw.png) An example usage of lazy loading in ruby (https://github.com/Shopify/graphql-batch)
An example usage of lazy loading in ruby (https://github.com/Shopify/graphql-batch)
If you’re like me, one thing that’s hard to get at first is when that perform method is called. We know resolvers won’t load data individually anymore, but when are these promises fulfilled? How does the GraphQL execution handle this? It turns out that will vary a lot based on the implementation and language. For example, Node.js has asynchronous primitives that allow this pattern to work quite well. This is why dataloader uses process.nextTick to batch load a set of keys. dataloader uses Node.js queue system to wait for all promises to have been enqueued, and then run the batch function. I won’t go into details here since Lee Byron has an amazing explanation that you can watch. I highly recommend you watch, at the very least the part about enqueuePostPromiseJob.
For other languages that don’t have these primitives, like ruby, the GraphQL library itself may have to handle this promise and batch handling. graphql-ruby calls this lazy execution. In a way this is similar to dataloader's approach, but it is much more coupled to the execution’s implementation. graphql-ruby will start executing a query, but will stop whenever it sees a lazy object, in our case, a Promise . Once it has executed every it could before moving on to the promises, it will call sync on all of them, causing the loaders to batch load data, and fulfill the promises. Let’s see it in action.
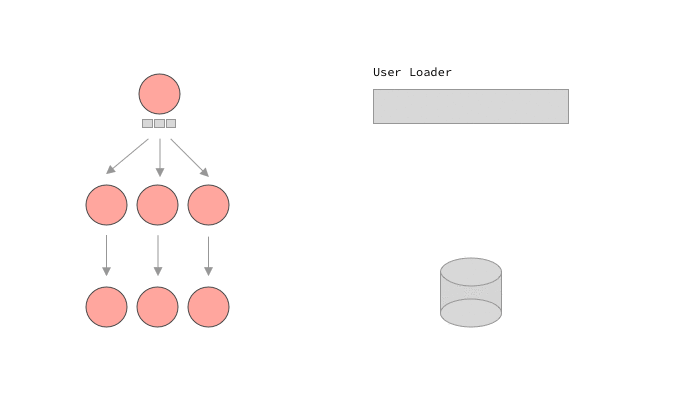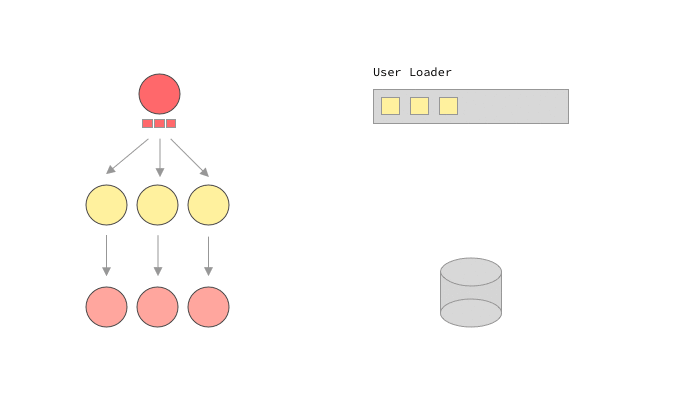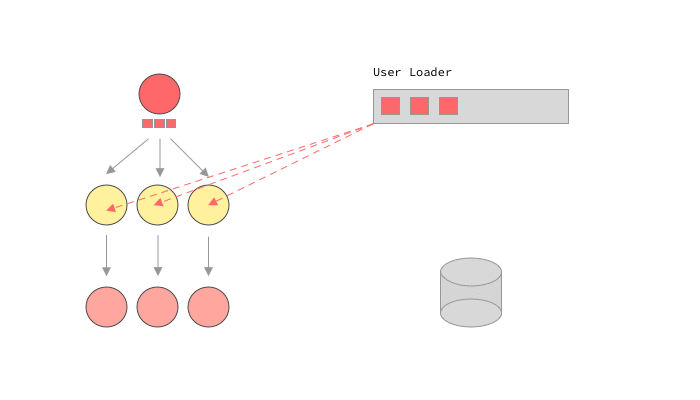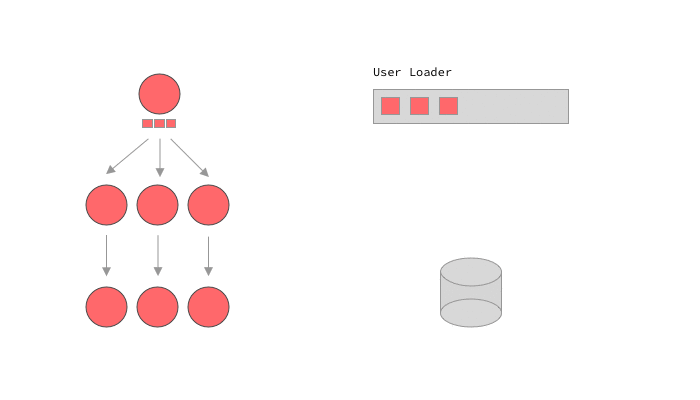 A GraphQL query execution using lazy loaders
A GraphQL query execution using lazy loaders
This is it! Of course it can get a lot more complicated than this, for example calling other loaders within the callback of our promises. The magic with lazy loading is that we don’t need to know exactly how the query will look or how exactly our clients will try to load data. We can let the execution lazily load what we need, and make sure that our loaders were well implemented.
Time for you to implement it! The Dataloader repo actually lists out a lot of language specific implementations - of this pattern that you can pick from.
I know lazy loading / dataloader-style loading can be a mystery at first but I hope this post shed some light it on it for some of you. Feel free to reach out if you have more questions!
— Marc