
Mutations are one of the trickiest part of a GraphQL schema to design. We spend a lot of time talking about GraphQL queries and how easy they are to use. However, mutations get far less love.
I spent the last few days thinking about how I think about mutation design, and how it relates RPC, REST, & domain driven design. I’ll be posting a series of posts on a few subjects related to GraphQL Mutation Design.
In this post, we’ll focus on what I’ve been calling Anemic Mutations.
Anemic Mutations ™️
There’s this thing called Anemic Domain Models in the domain driven design world. Explained quickly, the AnemicDomainModel is a pattern in which our domain model contains only data, without any of the behaviors associated with it.
I think we can make a pretty interesting link between this “Anti-Pattern” and designing a good mutation system in our GraphQL APIs. Here’s an example of what I would describe as an Anemic Mutation. Imagine a Checkout object, part of some e-commerce GraphQL schema:
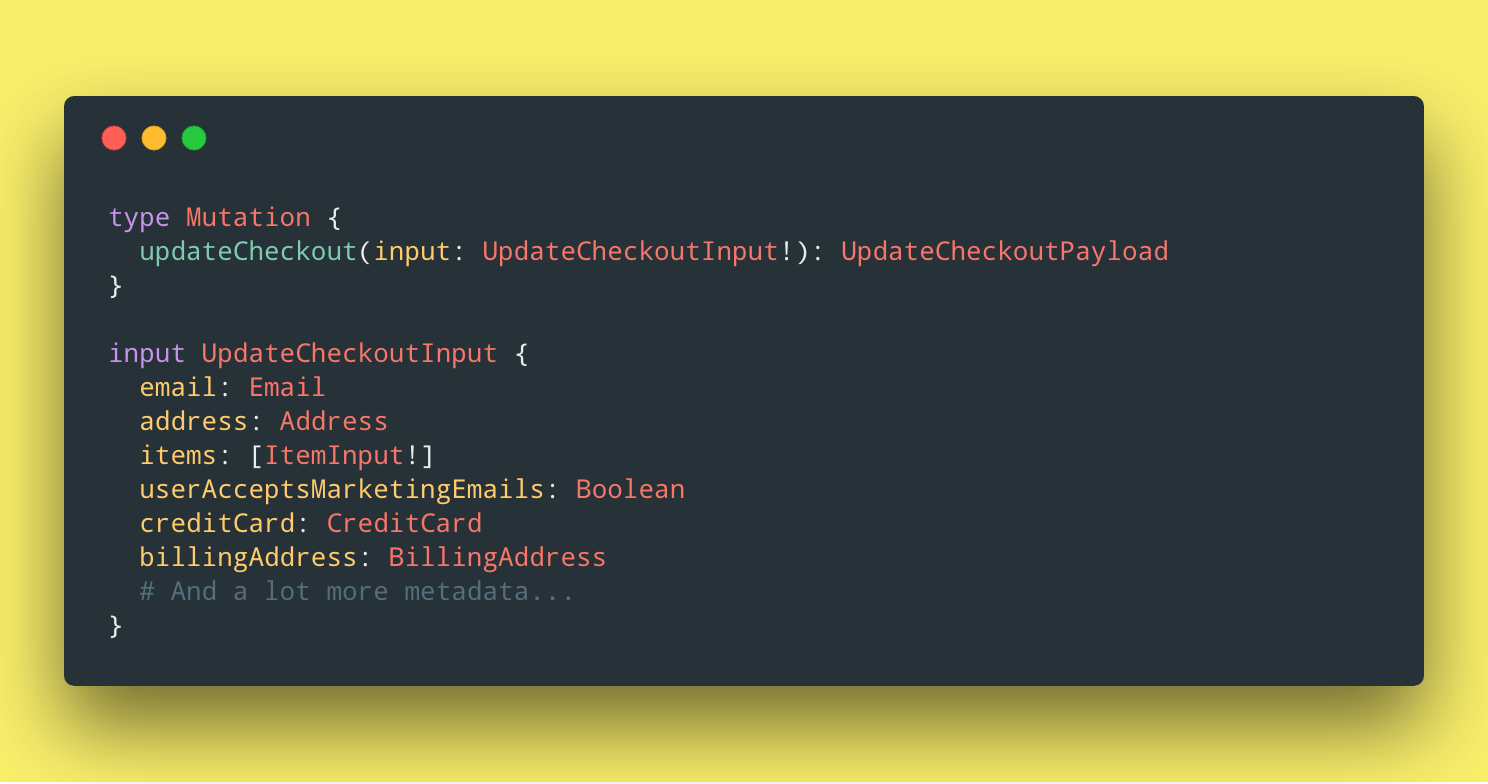
The first thing we can look at is how all the input fields on UpdateCheckoutInput are optional. Since they have opted for a simple CRUD mutation, and since they might want to allow partial updates during the checkout process, it makes sense at first to make everything optional. There’s a few things about this design that I really don’t like.
First, since we decided to use a “coarse grained” mutation that allows us to make any changes to this Checkout object, we had to make everything nullable (optional). One of GraphQL’s great strengths is its type system. By removing any nullability constraints on the input fields, we’ve pretty much deferred all this validation to the runtime, instead of using the schema to guide the API user towards proper usage.
The second point is what makes this mutation an AnemicMutation. We’ve designed the input type in a very data-centric way, instead of focusing on behaviors. Imagine for example that our API user wants to use the API to create a “Add To Cart” button:
- Because the mutation focuses so much on data, and not on behaviors, our clients need to guess how to make a specific action. What if adding an item to our checkout actually necessitates updates to a few other attributes? Our client would only learn that through errors at runtime, or worst, may end up in a wrong state by forgetting to update one attribute.
- We’ve added cognitive overload to clients because they need to select the set of fields to update when wanting to take a certain action, like “Add to Cart”.
- Because we focus on the shape of the internal data of a Checkout, and not of the potential behaviors of a Checkout, we don’t explicitly indicate that it’s even possible to do these actions, we let them guess by looking at our data model.
Lets look at how we could design this mutation so that it explicitly tells us how to add an item to a checkout:
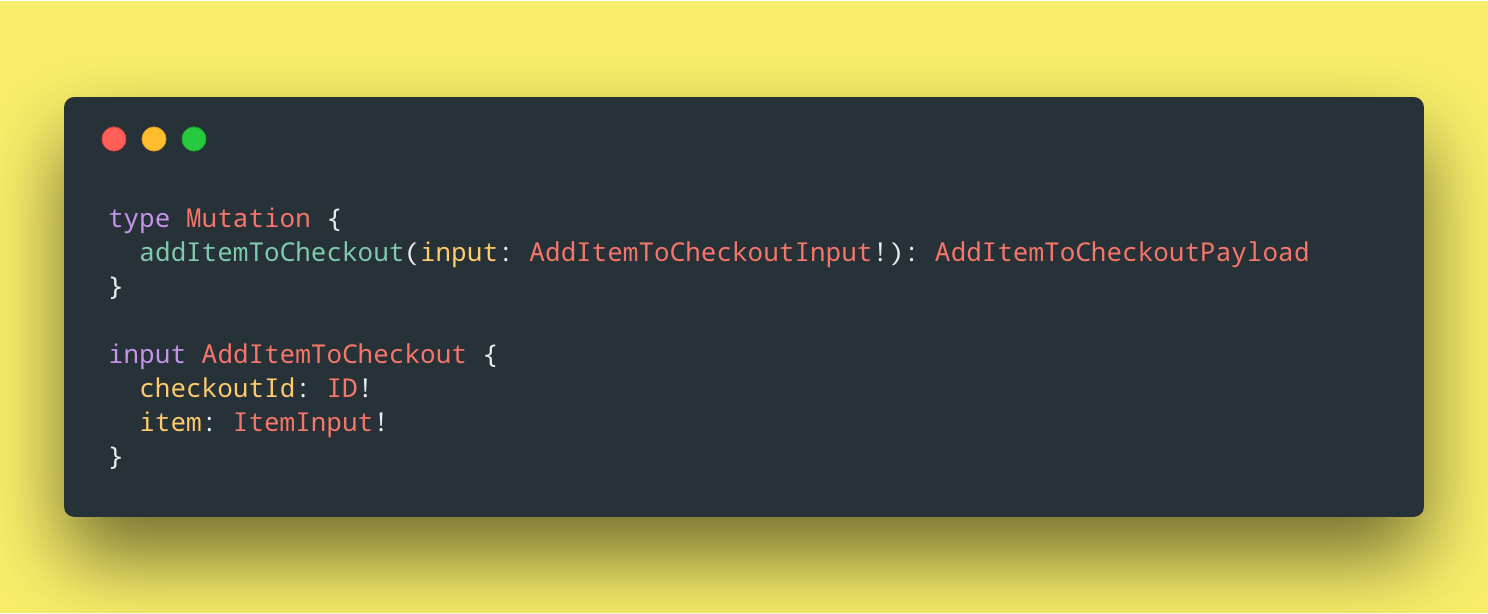
We’ve fixed most of the issues we talked about earlier:
- Our schema is strongly typed. Nothing is optional in this mutation, our clients know exactly what to provide to add an item to a checkout.
- No more guessing. Instead of finding which data to update, we add an item. Our clients don’t care about which data needs to be updated in these cases, they just want to add an item.
- The set of potential errors that may happen during the execution of this mutation has been greatly reduced. Our resolver can return finer grained errors.
- There’s no way for the client to get into a weird state by using this mutation because that’s handled by our resolver.
An interesting side-effect of designing mutations this way is that developing these mutations becomes way more straight forward on the backend. Since the mutation input is way more predictable, we can remove a lot of non-needed validations in the resolver. An other really cool thing is that emitting events also becomes easier. Imagine trying to emit a ItemAdded event every time some user adds an item to their checkout. In a big fat mutation with optional input fields, we need to check for every scenario with conditionals, and emit events depending on these conditions, it gets messy.
In a way, I find this ties in a lot with a few points Caleb Meredith made in his post (https://dev-blog.apollodata.com/designing-graphql-mutations-e09de826ed97) a while ago, which I really enjoyed.
Over the coming days and weeks, I’ll be publishing a few other posts on GraphQL mutation design. I’ll be writing on managing state with mutations, designing for static queries, and good argument design.
Thank for reading ❤️ If you’ve enjoyed this post, you could follow me on twitter! You would probably also enjoy The Little Book of GraphQL Schema Design that I’m working hard on finishing. It would mean a lot if you would subscribe for updates!